
Overview
Hightouch lets you pull data stored in Databricks and push it to downstream destinations. Hightouch connects to Databricks using Open Database Connectivity (ODBC). This guide walks you through getting your ODBC URL for your Databricks cluster and using your credentials to connect to Hightouch.
You can connect Databricks to Hightouch using Databricks Partner Connect to bypass the setup steps outlined below. You can learn more about this in Databricks' documentation.
You need to allowlist Hightouch's IP addresses to let our systems contact your warehouse. Reference our networking docs to determine which IPs you need to allowlist.
Databricks credential setup
-
In your Databricks Account console, go the Workspaces page. Select the relevant workspace and then click Open workspace.
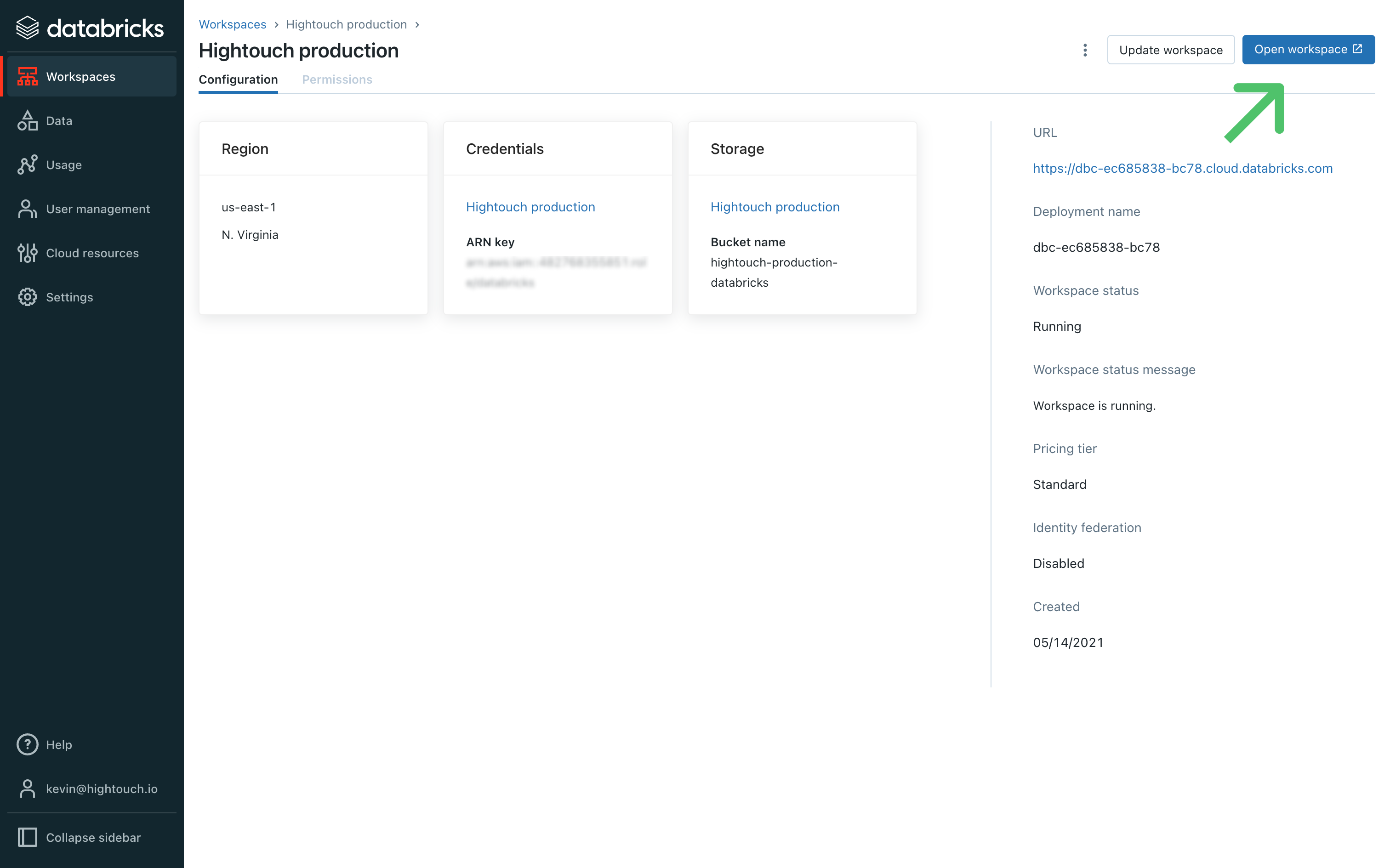
-
In your workspace, go the Compute page and click the relevant cluster. This brings you to its Configuration tab.
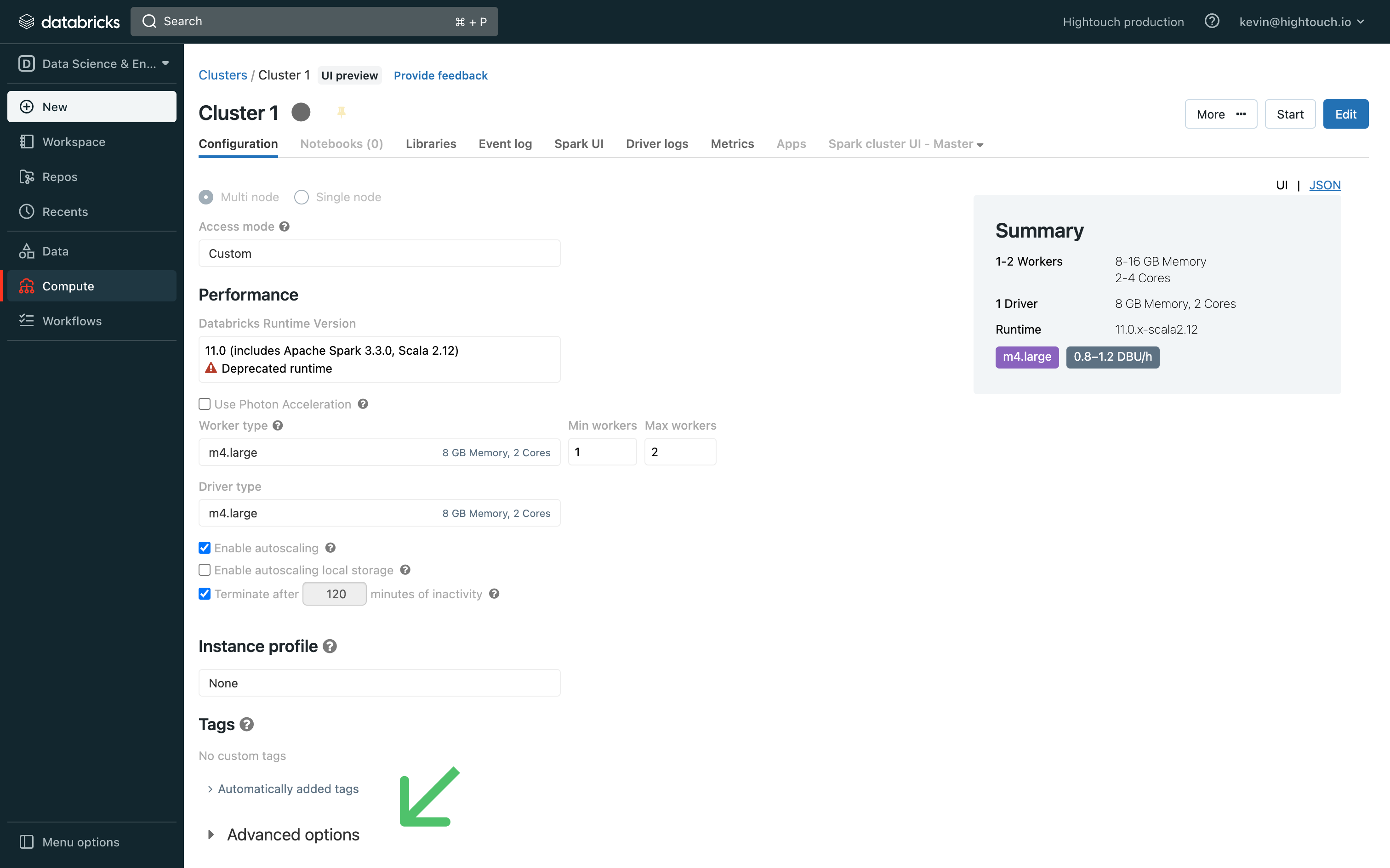
-
At the bottom of the page, expand the Advanced Options toggle and open the JDBC/ODBC tab.
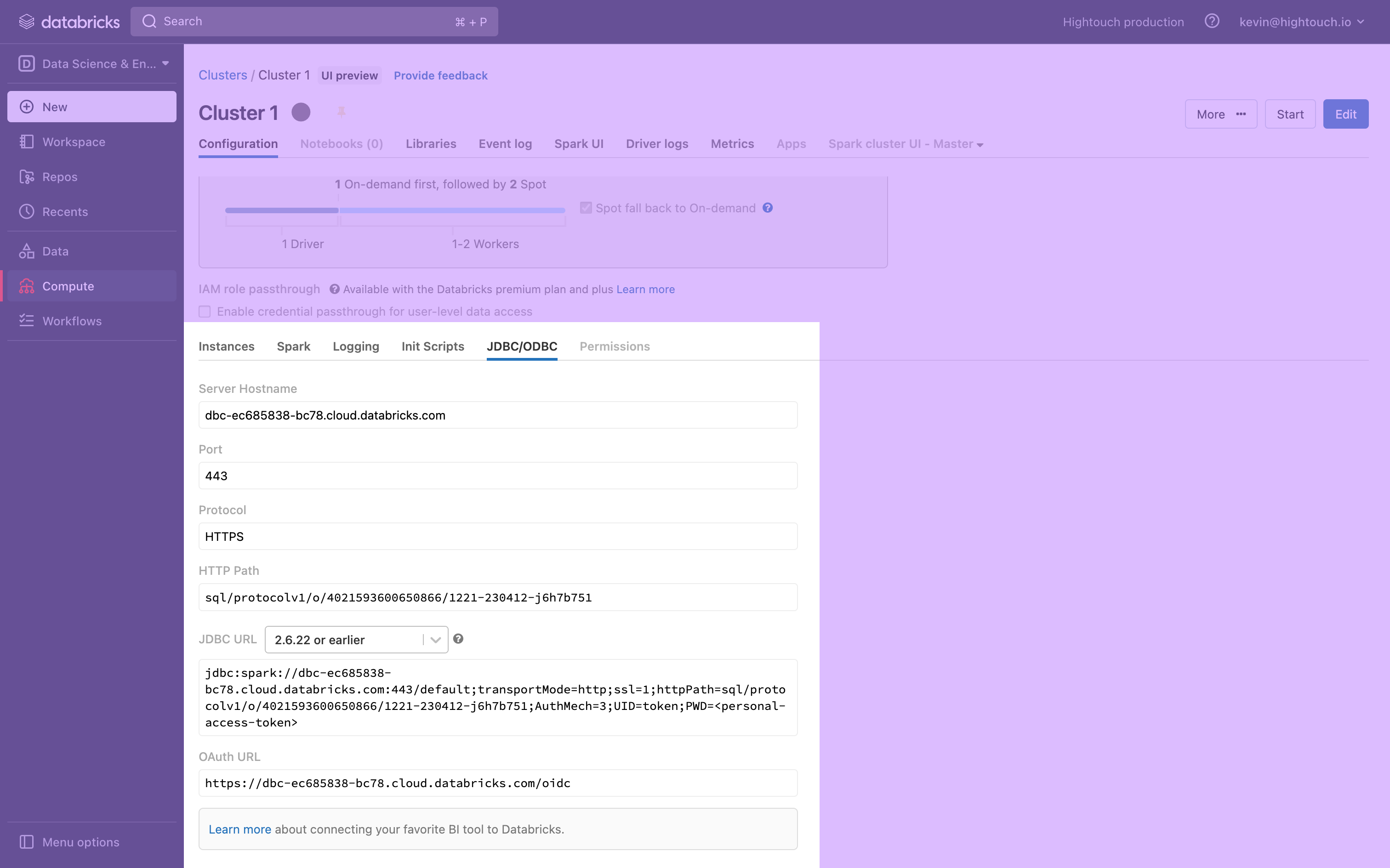
-
This tab displays your cluster's Server Hostname, Port, and HTTP Path, which you need to connect to Hightouch. Keep the tab open, or save these to a secure location.
-
Create a Personal access token by following the Databricks documentation.
Once you've saved these Databricks credentials, you're ready to set up the connection in Hightouch.
Connection configuration
To get started, go to the Sources overview page and click the Add source button. Select Databricks and follow the steps below.
Configure your source
Enter the following required fields into Hightouch:
- Server hostname: To find your server hostname, visit the Databricks web console and locate your cluster. Then, click to reveal Advanced options and navigate to the JDBC/ODBC tab.
- Port: The default port number is 443, but yours may be different. To find your port, visit the Databricks web console and locate your cluster. Then, click to reveal Advanced options and navigate to the JDBC/ODBC tab.
- HTTP path: To find your HTTP path, visit the Databricks web console and locate your cluster. Then, click to reveal Advanced options and navigate to the JDBC/ODBC tab.
- (Optional) Catalog: You can optionally include a Databricks catalog. Catalogs are the first level of Unity Catalog's three-level namespace. If you specify a catalog, only schemas from that catalog are available.
- Schema: The initial schema to use for the connection.
- SQL dialect: By default, Hightouch assumes that your queries use the Databricks SQL dialect. You may wish to override this behavior if your queries use legacy ANSI SQL-92 syntax. Some features are not available when legacy syntax is used.
Choose your sync engine
For optimal performance, Hightouch tracks incremental changes in your data model—such as added, changed, or removed rows—and only syncs those records. You can choose between two different sync engines for this work.
The standard engine requires read-only access to Databricks. Hightouch executes a query in your database, reads all query results, and then determines incremental changes using Hightouch's infrastructure. This engine is easier to set up since it requires read—not write—access to Databricks.
The Lightning engine requires read and write access to Databricks. The engine stores previously synced data in a separate schema in Databricks managed by Hightouch. In other words, the engine uses Databricks to track incremental changes to your data rather than performing these calculations in Hightouch. Therefore, these computations are completed more quickly.
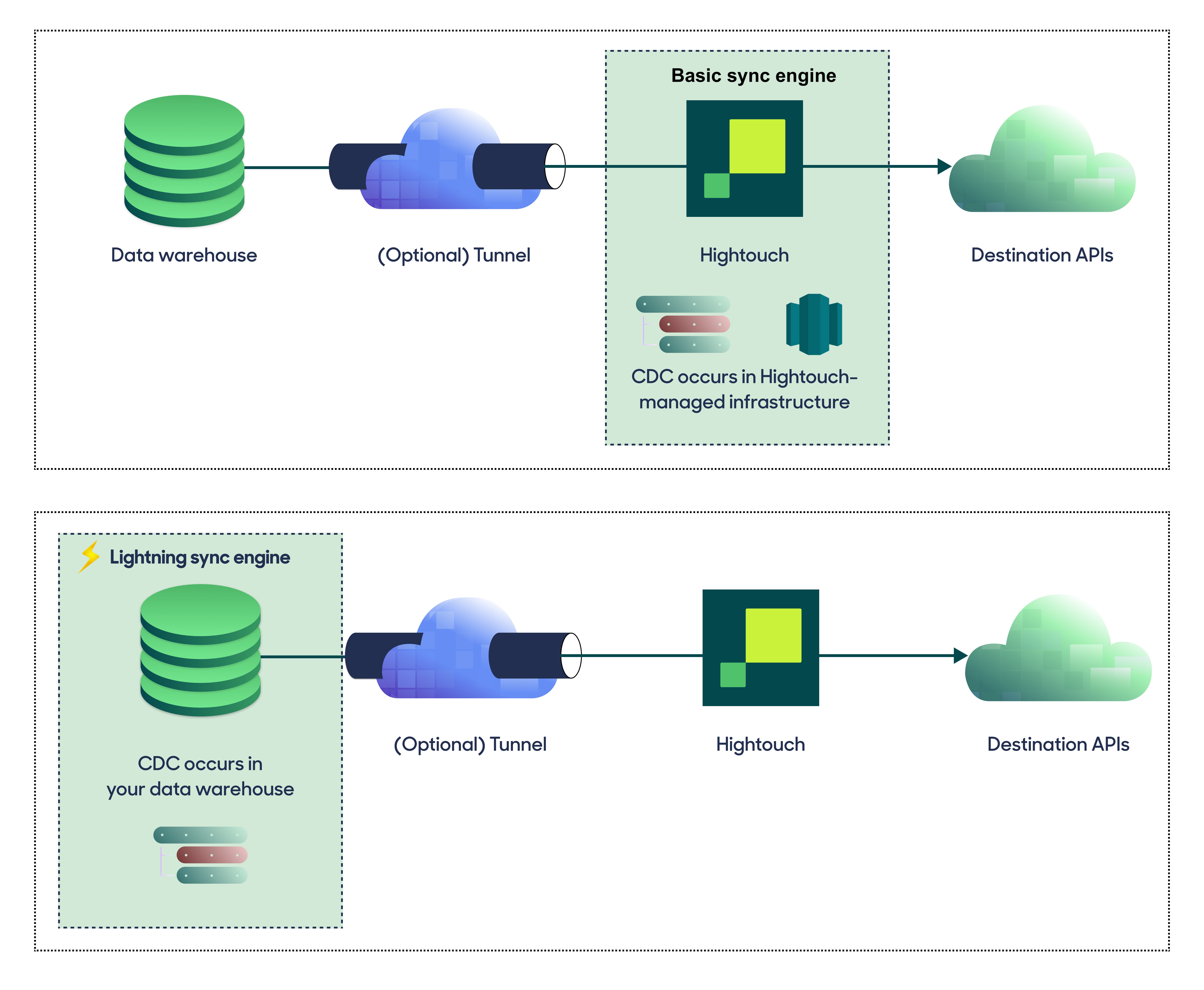
If you select the standard engine, you can switch to the Lightning engine later. Once you've configured the Lightning engine, you can't move back to the standard engine without recreating Databricks as a source.
To learn more, including migration steps and tips, check out the Lightning sync engine docs.
Standard versus Lightning engine comparison
The Lightning sync engine requires granting write access to your data warehouse, which makes its setup more involved than the standard sync engine. However, it is more performant and reliable than the standard engine. This makes it the ideal choice to guarantee faster syncs, especially with large data models. It also supports more features, such as Warehouse Sync Logs, Match Booster, and Identity Resolution.
| Criteria | Standard sync engine | Lightning sync engine |
|---|---|---|
| Performance | Slower | Quicker |
| Ideal for large data models (over 100 thousand rows) | No | Yes |
| Reliability | Normal | High |
| Resilience to sync interruptions | Normal | High |
| Extra features | None | Warehouse Sync Logs, Match Booster, Identity Resolution |
| Ease of setup | Simpler | More involved |
| Location of change data capture | Hightouch infrastructure | Databricks schemas managed by Hightouch |
| Required permissions in Databricks | Read-only | Read and write |
| Ability to switch | You can move to the Lightning engine at any time | You can't move to the standard engine once Lightning is configured |
Lightning engine setup
To set up the Lightning engine, ensure that your Databricks user or service principal has the appropriate permissions. You can do so by running the following SQL snippet.
Before running the snippet, make sure to include your own username, which can be found in the top right corner of the Databricks web console. Alternatively, you can create an API-only service principal by following these instructions.
CREATE SCHEMA IF NOT EXISTS hightouch_audit;
CREATE SCHEMA IF NOT EXISTS hightouch_planner;
GRANT OWNERSHIP ON SCHEMA hightouch_audit TO ROLE identifier($ht_default_role);
GRANT OWNERSHIP ON SCHEMA hightouch_planner TO ROLE identifier($ht_default_role);
Provide credentials
Enter the Access token you generated in the Databricks credential setup.
Test your connection
When setting up a source for the first time, Hightouch validates the following:
- Network connectivity
- Databricks credentials
- Permission to list schemas and tables
- Permission to write to
hightouch_plannerschema - Permission to write to
hightouch_auditschema
All configurations must pass the first three, while those with the Lightning engine must pass all of them.
Some sources may initially fail connection tests due to timeouts. Once a connection is established, subsequent API requests should happen more quickly, so it's best to retry tests if they first fail. You can do this by clicking Test again.
If you've retried the tests and verified your credentials are correct but the tests are still failing, don't hesitate to .
Next steps
Once your source configuration has passed the necessary validation, your source setup is complete. Next, you can set up models to define which data you want to pull from Databricks.
The Databricks source supports these modeling methods:
- writing a query in the SQL editor
- using the visual table selector
- leveraging existing dbt models
- leveraging existing Sigma workbooks
The SQL editor allows you to query data from all databases that your Databricks credentials have access to, unless you specify a catalog. The table selector only supports querying from the schema specified in the source configuration.
You may also want to consider storing sync logs in Databricks. Like using the Lightning sync engine versus the standard one, this feature lets you use Databricks instead of Hightouch infrastructure. Rather than performance gains, it makes your sync log data available for more complex analysis. Refer to the warehouse sync logs docs to learn more.
You must enable the Lightning sync engine to store sync logs in your warehouse.
Tips and troubleshooting
If you encounter an error or question not listed below and need assistance, don't hesitate to . We're here to help.
Unity Catalog support
Hightouch integrates with Databricks' Unity Catalog feature. During initial configuration, just make sure to include a catalog.
Subquery error
Some Databricks models return the following error:
java.lang.IllegalArgumentException: requirement failed: Subquery subquery#485, [id=#937] has not finished {...}.
This error can occur when the model query contains a subquery, especially when the subquery has an ORDER BY clause. For example:
SELECT user_query.*
FROM (
SELECT * FROM default.subscriptions_table
ORDER BY last_name
) user_query.*
The best way to resolve the error is to rewrite your model query to remove subqueries. Common table expressions (CTE) are supported. If you require assistance, don't hesitate to .
Error connecting to the database. Unauthorized/Forbidden: 403
This error can occur when testing the source connection or when running a sync that uses a Databricks model. It is typically caused by an expired Databricks access token. To solve this, generate a new token and insert it in the source configuration.